Fixing Playwright Tests with AI: What to Fix, What to Flag
AI can fix Playwright tests now. What to fix, what to flag, and how TestDino MCP proves a fix held.






AI can fix Playwright tests now. What to fix, what to flag, and how TestDino MCP proves a fix held.A failing Playwright test gives you 1 line: Timeout 30000ms exceeded, or locator resolved to 0 elements. That line is a symptom, not a cause. The same message can mean a renamed button, a slow API in CI, a feature flag that flipped, or a real bug your test just caught.
In 2026, Playwright can patch that itself: it ships agents that read the live page, diagnose the failure, fix the test, and re-run it. AI can now fix Playwright tests, not just explain them.
The catch is the part most write-ups skip. "Make the test pass" is the wrong goal. A test that goes green because the AI loosened an assertion until it stopped complaining is worse than a red one: it hides a regression and reports success while doing it.
The useful question is narrower: which failures should AI fix, which should it refuse, and how do you confirm a fix actually holds rather than turns this run green?
This guide walks through what the tooling does today and where the safe boundary sits. The last part, proving a fix held across runs instead of trusting a single pass, is where the TestDino MCP server comes in: it hands your AI agent the run history the healer can't see.
Fixing Playwright tests with AI: What changed in 2026
The shift is that the framework now does this itself. Playwright v1.56 (released late 2025) introduced Test Agents: 3 built-in agent definitions that guide an LLM through building and maintaining a suite. Per the official release notes, they are:
- Planner: explores the app and produces a Markdown test plan.
- Generator: turns that plan into executable Playwright Test files, verifying selectors and assertions against the live app as it writes.
- Healer: executes the suite and automatically repairs failing tests.
You install them with npx playwright init-agents (with definitions for VS Code, Claude Code, and OpenCode). The agents run on top of the Model Context Protocol, the open standard Anthropic introduced in late 2024, which is what lets an LLM call structured tools rather than guessing from screenshots.
If you are wiring this up for the first time, our Playwright MCP walkthrough covers what the protocol exposes to an agent and why it matters here.
Meet the Playwright healer agent
The healer is the one that "fixes" tests, so it's worth being precise about what it actually does, because there is a lot of inflated description floating around. For the wider authoring side of this (planner and generator), see TestDino's breakdown of Playwright Test Agents. This piece stays on the healer and the fix-verification problem.
How the Playwright healer agent works
The healer runs a 4-step loop, documented in Playwright's test-agents docs and Microsoft's published healer agent spec:
- Replay the failing steps in debug mode. It re-runs the specific failing test, not the whole suite, so it can watch the failure happen.
- Inspect the current UI. It reads the page's accessibility-tree snapshot, console messages, and network requests, the same structured signals Playwright MCP exposes, to find the element or flow the test was reaching for.
- Classify the root cause. It sorts the failure into one of the 3 categories: a selector that changed, a timing or synchronization problem, or a genuine change in the application.
- Patch and re-run. It applies a fix (a locator update, a wait adjustment, an assertion change, or a data fix) and runs the test again. It repeats until the test passes or a guardrail stops the loop.

A concrete example from the Playwright team:
- A test used getByRole('textbox', { name: 'Country' }), but the app had switched that field to a combobox.
- The healer read the accessibility snapshot, saw the role mismatch, rewrote the locator to use getByRole('combobox', { name: 'Country' }), and re-ran to confirm.
- In another case, it found a snapshot with 2 heading elements, whereas the assertion expected only 1.
- It loosened the regex so the assertion matched reality; re-ran again before declaring the fix good.
That re-run-before-declaring step matters. The healer doesn't propose a patch and walk away; it validates the patch against a live run. But validating against 1 run is exactly where the harder question starts, and we'll come back to it.
What to fix and what to flag
Every failing test sorts into 1 of 2 buckets, and the whole safety question turns on which bucket it falls into. Either the test's path to the element drifted while its intent stayed correct (fix it), or the app's behavior changed, and the test caught it (flag it). The next 3 sections walk that split.
What AI can safely fix
The failures AI handles well share a trait: the test's intent is still correct, and only the path to the element drifted. The app didn't break; the test's description of the app went stale.
- Changed locators / DOM drift. A renamed button, a restructured form, a role that changed from textbox to combobox. The element still exists and still does its job; the selector points at an old shape.
- Timing and synchronization. A step that races a slow network call or a late-rendering element. The fix is usually waiting on the right signal (waitForResponse() on the real request) instead of a hardcoded delay, and Playwright's auto-waiting handles most of the rest.
- UI-driven assertion drift. An assertion that's stricter than the UI now warrants, where the page legitimately changed, and the check needs to match it.
These are safe because the AI can see everything it needs in the accessibility tree to confirm the fix. The element is right there; the agent reads its role, name, and state, and verifies the corrected locator resolves. Nothing about the app's correctness is in question, so there's no hidden regression for the fix to mask.
This is also the maintenance work that eats the most QA time, the routine churn from UI changes rather than real defects. Automating it is genuinely useful, and it's the bulk of how teams reduce test maintenance without lowering coverage. The line to hold is the next section.
What AI should not auto-fix
The failures AI should refuse share the opposite trait: the test is right, and the app is wrong. Here, "fixing" the test means deleting the evidence of a bug.
- Backend and API contract changes. A response shape changed, an endpoint returns a 500, a save operation fails with a fetch error. The healer reads the front end; it has no visibility into whether the backend's new behavior is intended or broken.
- Feature flags and configuration. A flag flipped, and a flow disappeared. A failing test is the correct signal that the behavior has changed; auto-adapting hides the change.
- Multi-tenant data models and test-state issues. Failures that depend on which tenant, which seed data, or what state a previous test left behind. The AI can't reason about data it can't see.
- Multi-step business logic. A checkout that computes the wrong total, a permission check that lets the wrong role through. The locators all resolve; the logic is wrong, and that's invisible to an agent reasoning over the page's structure.
There's a fifth, subtler risk that cuts across all of these: hallucinated assertions. An LLM can rewrite an assertion to something that looks plausible and passes, but doesn't actually describe correct behavior. The test goes green, the reasoning reads convincingly, and the check now verifies nothing. This is why "the explanation sounded right" is not the same as "the fix is right."
Playwright's healer was designed with this boundary in mind, and its guardrail is the most important detail in the whole feature.
The test.fixme() guardrail
When the healer has high confidence that the test is correct but can't fix the failure through code, it does not force the test green or silently skip it. Per Microsoft's healer agent spec, it marks the test test.fixme() and adds a comment before the failing step explaining what's happening instead of the expected behavior.
In the Playwright team's own walkthrough, the healer hit a save that failed with a backend error, judged it "likely a backend issue," and marked the test test.fixme() with a note rather than patching around it. That's the framework saying, in code, "this is a real problem for a human, not a test to silence."
That single behavior settles the design debate: even the official tool treats "make it pass" as the wrong goal when passing would be a lie. The fix for a real bug is a ticket, not a patch.
A decision matrix from failure-type to fix-strategy
The boundary above collapses into a single table. Before letting an agent touch a failing test, the question is always the same:
Did the test's path to the element drift, or did the app's behavior change?
| Failure type | What actually broke | Safe for AI to fix? | Right action |
|---|---|---|---|
| Changed locator / DOM drift | Selector points at old shape; element still exists | ✅ | Let the agent update the locator, then verify across runs |
| Timing/synchronization | Step races a network call or late render | ✅ | Wait on the real signal; confirm stability over repeats |
| UI-driven assertion drift | Page legitimately changed | ⚠️ | Update the assertion, then human-confirm it still describes correct behavior |
| Backend / API contract change | App behavior changed or broke | ❌ | Investigate; file a bug if unintended |
| Feature flag/config change | A flow appeared or vanished by design | ❌ | Confirm intent with the team before changing the test |
| Test-data / state | Depends on data the agent can't see | ❌ | Fix the data setup, not the assertion |
| Multi-step business logic | Logic is wrong; locators all resolve | ❌ | Treat the red test as a caught regression |
| Hallucinated assertion (any type) | AI rewrote the check to something plausible but false | ❌ | Reject; require the assertion to match observed correct behavior |
The pattern we see is that green rows are about finding the element, while red rows are about judging the behavior. AI is strong at the first and structurally blind to the second.
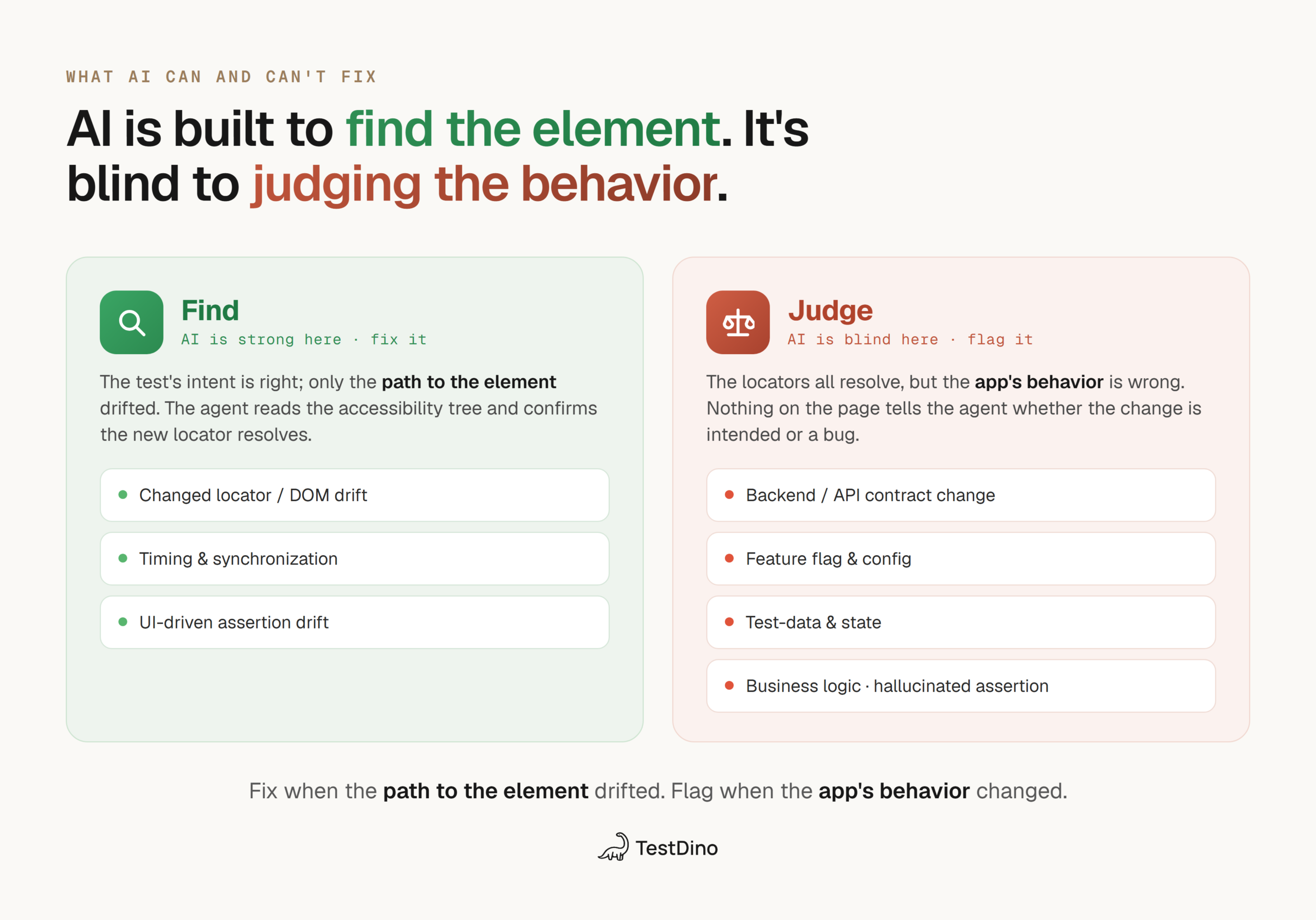
Why "make the test pass" is the wrong goal
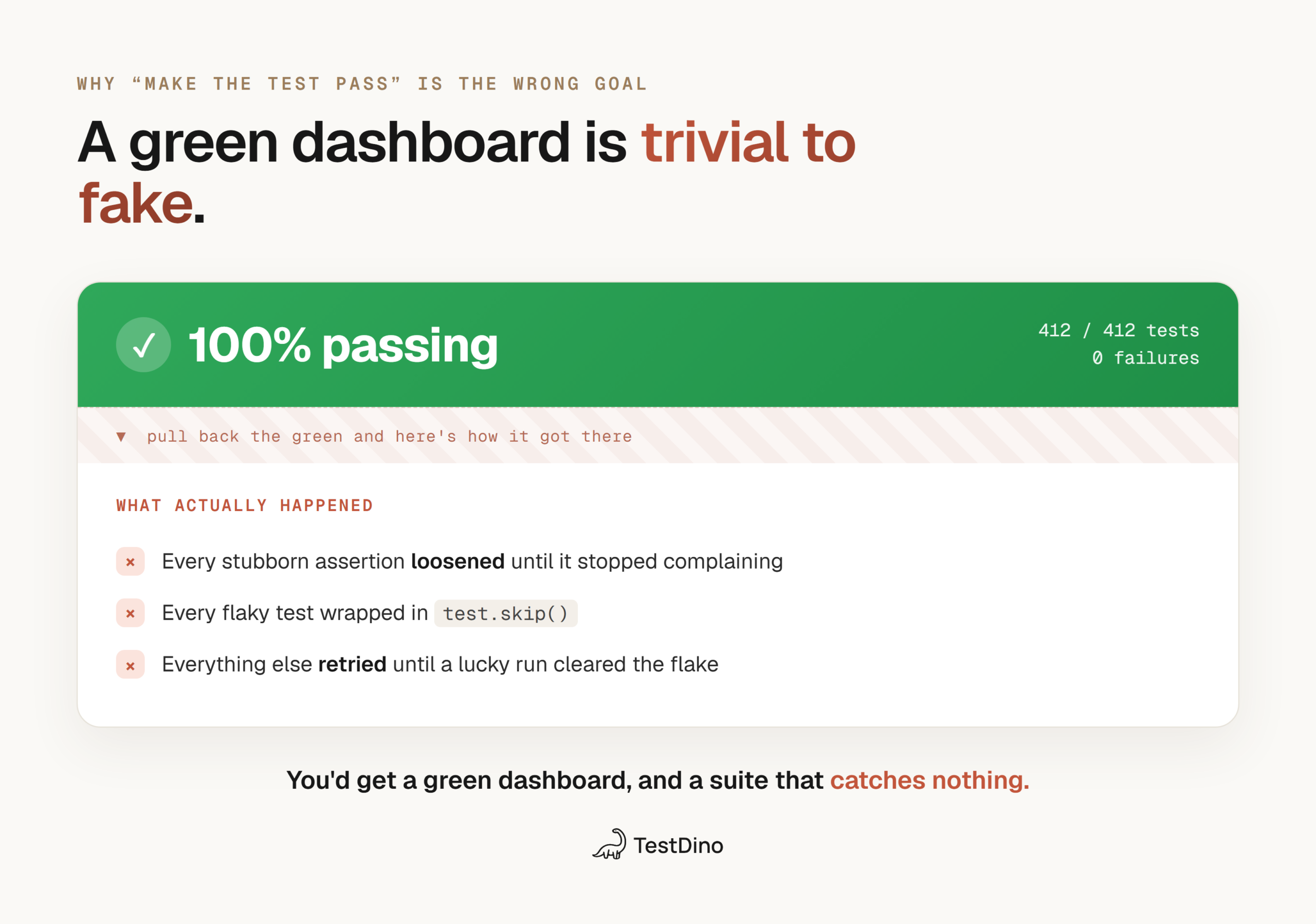
It's worth saying plainly because the entire category of "self-healing tests" is marketed on pass rates. A higher pass rate is trivial to manufacture: loosen every assertion, skip every stubborn test, retry until the flake clears. You'd get a green dashboard and a suite that catches nothing.
The job of a test is to fail when the product is wrong. A fix that's measured only by "the test now passes" optimizes against that job. The right success metric for an AI fix has 2 parts:
- The test still asserts what it was meant to assert. The intent survived the patch. A locator update keeps the original check intact; an assertion that got quietly weakened does not.
- The fix is stable, not just green once. A test that passes on the run the agent watched, then flakes on the next 10 wasn't fixed; the agent just caught a lucky run.
The first is a review question, answered by a human reading the diff. The second is a data question, and it's the one a single run can't answer, because the evidence lives in the suite's history, not on the page in front of the agent.
The failure the healer can't see
Picture the failure you actually dread. Not the renamed button. The test that passed on the run the agent watched, then went red 3 deploys later, on the CI runner in one region, one run in twenty. The healer looked at a single snapshot, saw a slow step, "fixed" it with a longer wait, and declared victory. The wait was never the problem. The test was intermittent, and now the flake is buried under a patch that makes it look like it was handled.
This is the structural blind spot. The healer reasons over 1 run: the page in front of it. That's exactly right for: "Which locator matches this element," and Playwright MCP serves it well, handing the agent the accessibility tree (role, name, state, hierarchy) as compact structured text rather than pixels or raw DOM.
But "does this fail every time or one run in twenty?" "Did it start after a specific deploy?" "Is this 1 flake or 50 tests failing on the same error?" Is not answerable from a single snapshot. They are properties of the suite's history, and an agent that can't see that history will confidently paper over them.

The 2 bars a healed test still has to clear
So a healed test isn't a fixed test. It's a candidate fix that still has to clear 2 bars; the run that produced it can't measure:
- Is it stable, or just green once? A locator fix should pass every time. If it passes 8 out of 10 reruns, the real problem was flakiness, and the "fix" hid it. (Playwright's --repeat-each exists precisely to shake this out, but only if something is watching the result across those runs.)
- Did it lower the bar? Confirm the patch changed the path to the element, not the standard the test holds the app to. A loosened assertion needs a human to confirm the looser check still describes correct behavior.
Answering both by eye, per fix, doesn't survive past a handful of tests. What closes the loop is run history: the record of how that specific test behaved across every run, before and after the patch. That's a different layer from the live page, and it's the layer the healer doesn't have.
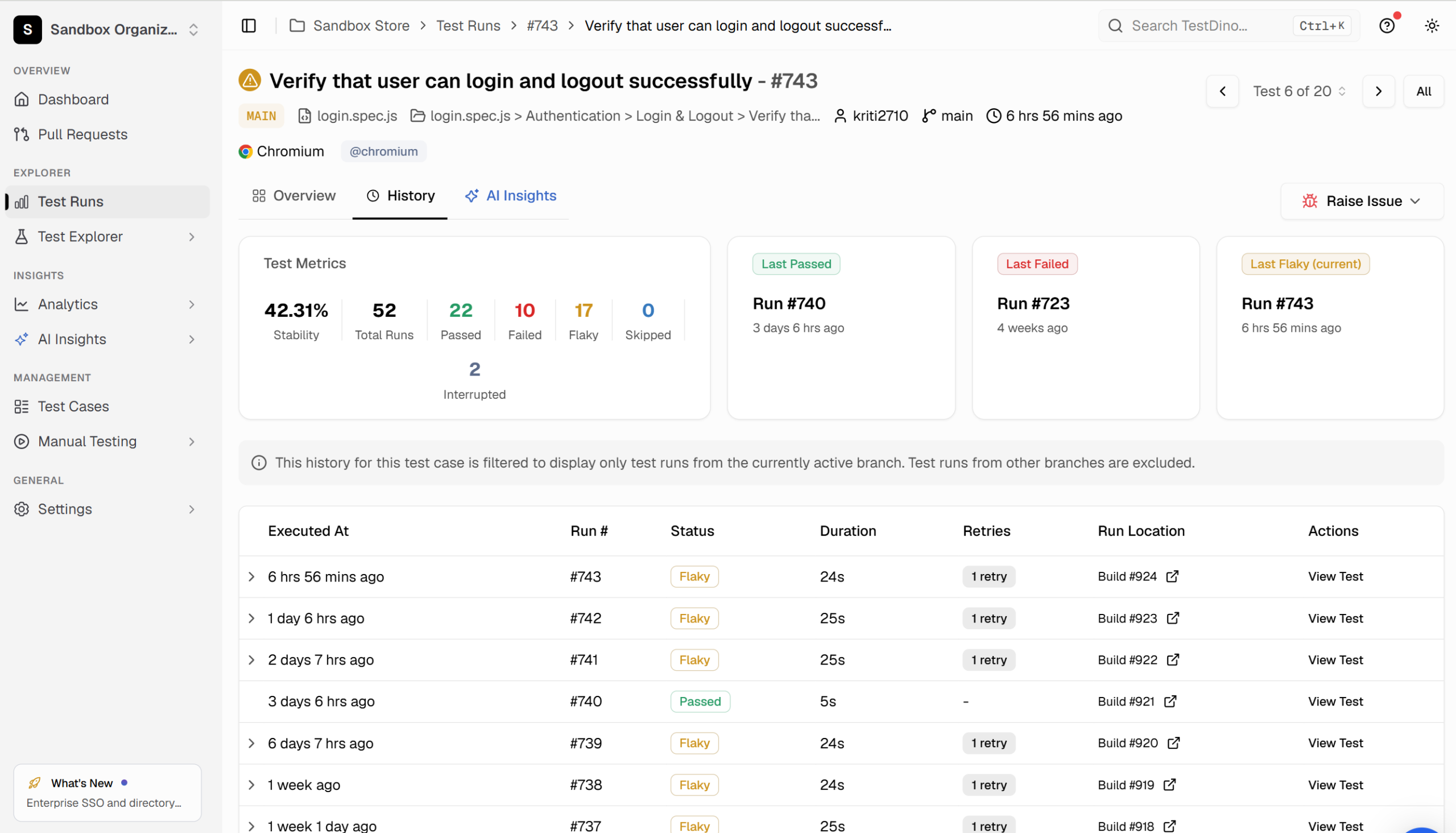
Giving the agent the run history: TestDino MCP
This is the layer TestDino sits on. TestDino is a Playwright observability platform: it captures the results of every run, whether it happened in CI, in a cloud agent's sandbox, or on a local machine, and retains traces, screenshots, videos, console logs, and the run-over-run trend for each test. Its MCP server exposes that history to an AI agent as callable tools, so the agent that just patched a test can ask, in the same chat, whether the patch actually held.
What the run-history layer adds
Where Playwright MCP answers "what's on the page right now?", the TestDino MCP server answers "how has this test behaved across every run?". That's the missing half of the verification loop. Concretely, an agent connected to it can, in plain language:
- Pull a test's run history and reruns (get_testcase_details) to tell a real fix from a lucky pass: did the patched test go green and stay green across the next runs, or is it still flickering?
- Run a root-cause analysis over historical executions (debug_testcase, which the docs describe as analyzing historical execution data to suggest root-cause fixes) so a timing patch is checked against whether the failure was ever a timing problem to begin with.
- Detect and rank flaky tests across runs, so a "fixed" test that's actually intermittent gets caught instead of trusted.
- Group failures by error and root cause (get_run_details), so the agent can see whether this red test is isolated or part of a pattern that hits 50 tests after a deploy, the difference between a one-line patch and a rolled-back release.
The run-history tools the agent calls
Those questions map onto specific tools. The server exposes 27 in total (across analysis, manual testing, releases, and exploratory sessions); the handful that matter for verifying an AI fix are the analysis tools that read run history:
| TestDino MCP tools | Their use |
|---|---|
| get_testcase_details | Pull one test's run history and reruns to tell a real fix from a lucky pass. |
| debug_testcase | Root-cause a failure over its historical executions, not just this run. |
| Root cause_details | Group a run's failures by error to see if a red test is isolated or a pattern. |
| list_testcase (isFlaky) | Filter for flaky tests across runs so an intermittent "fix" gets caught. |
| list_testruns | List recent runs for a project or branch to compare before and after a patch. |
| create_release | Cut a release from chat once the history confirms the suite is clean. |
One-click connect
Connecting used to be the friction point: generate a token, copy it, edit a JSON config, restart the client. TestDino recently collapsed that into 1 step. You paste one URL (mcp.testdino.com) and approve it in the browser, with a scope picker to specify exactly which projects and modules the connection can access.
Beyond verification: Drive the workflow from chat
Once connected, the agent isn't limited to verification. Because the same server exposes test runs, manual cases, and releases as tools, you can drive a chunk of the testing workflow from chat, asking which tests are flaky this week, triaging a failing run, or cutting a release without leaving the conversation.
The server is open source (github.com/testdino-hq/testdino-mcp), and it sits alongside TestDino's other Playwright tooling, including the playwright-skill best-practices guide for AI agents and the broader TestDino-Plugins collection.
The shape of the full loop, then: the healer (or your own agent) proposes a fix from the live page; the run-history layer confirms, across every recorded run, that the test now passes consistently and didn't quietly lower its standards. The first half makes the test green. The second half makes it trustworthy. A fix isn't done until both are true.
How to use this safely
The tooling is good and getting better, but the boundary is yours to hold:
- Review every fix, even when the reasoning reads well. AI constructs convincing explanations for wrong fixes; a plausible rationale is not evidence.
- Guard assertions hardest. Locator and timing fixes are low-risk. An assertion change is the one place where a "fix" can silently delete coverage, so confirm that the new check still describes the correct behavior.
- Trust test.fixme() over a forced pass. When an agent flags a failure as a likely real bug, that's the system working. Investigate it; don't reach for a patch that makes it green.
- Verify across runs, not on 1 pass. A single green run is the start of trusting a fix, not the end. Give the agent the run history, or confirm only that this run is green.
Used this way, AI takes routine maintenance, locator churn, and timing waits off your plate, while the failures that actually matter still reach a human. That's the version of "fixing Playwright tests with AI" worth running: faster on the noise, honest about the signal.

FAQs
Table of content
Flaky tests killing your velocity?
TestDino auto-detects flakiness, categorizes root causes, tracks patterns over time.
Follow Us